Conception de site web :
les différentes approches
Cinq modèles de conception de site web schématisés et expliqués.
Cinq modèles de conception de site web schématisés et expliqués.

Pour une agence web basée à Rennes ou ailleurs, la complexité de notre travail réside dans l’appréhension de différentes conceptions de sites web. Il nous faut les comprendre, reconnaître leurs avantages et leurs inconvénients et enfin l’expliquer à nos collaborateurs internes, externes et bien sûr à nos clients.
C’est ce que nous allons tenter de faire avec une série de schémas présentant 5 modèles de conception de sites web. Nous les avons classés par ordre chronologique d’apparition dans la sphère web. Alors c’est certainement très schématisé, mais l’important est de bien comprendre les mécanismes sur lesquels reposent ces modèles.
L’idée est aussi de vous donner quelques chiffres sur la web performance attendue sur chacun des modèles. Bonne lecture.
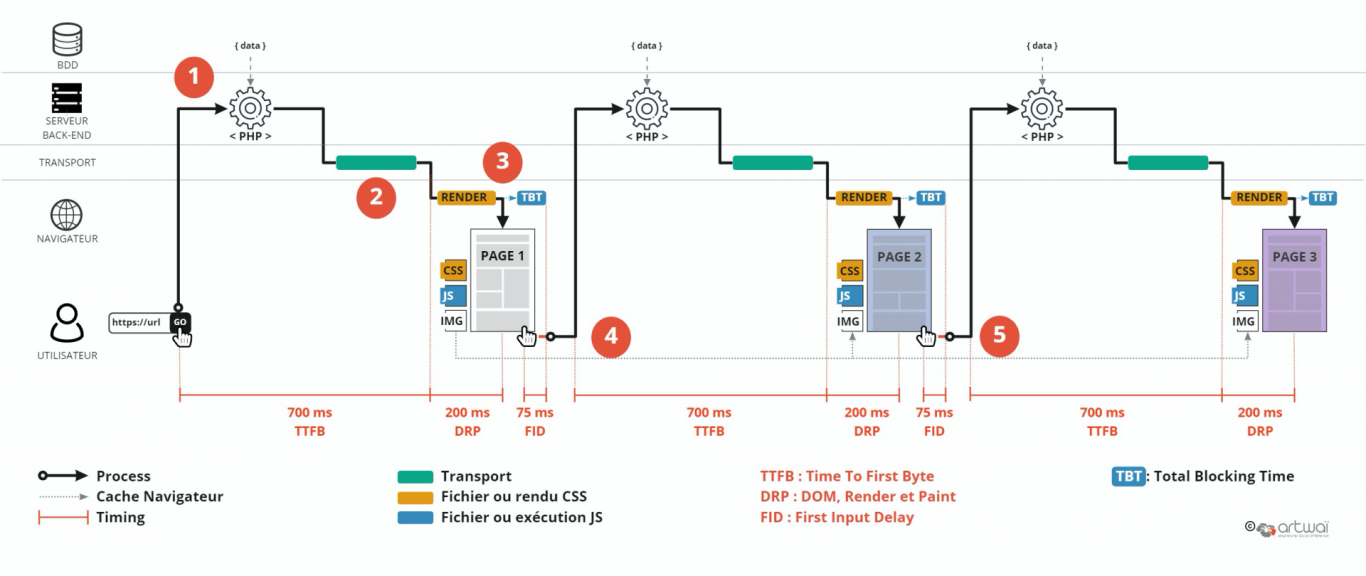
N’en déplaise aux développeurs, cela reste le modèle de conception de site web le plus utilisé. La plupart des CMS, dont WordPress, sont basés sur celui-ci. Sa caractéristique est surtout d’avoir les requêtes aux données (en SQL par exemple) inclus dans le templating (le code HTML).
D’un point de vue code, c’est pas terrible. D’un point de vue organisation non plus. Généralement, ceux qui font le templating ne sont pas les mêmes que ceux qui font les requêtes aux datas. A l’inverse pour des projets simples, tout est regroupé au même endroit ce qui est souvent plus compréhensible.
Toutefois, il y a aujourd’hui des modèles de conception (dites MVC) qui prennent soin, sur le serveur, de séparer accès aux données et templating, comme avec Symfony. C’est généralement plus contraignant mais plus évolutif aussi.
Peu importe comment est construit la page sur le serveur, là, c’est son poids et sa complexité qui vont déterminer les temps de chargement et d’affichage. Pour l’exemple, je me suis basé sur les temps relevés avec un profil mobile/3G avec ce modèle de conception de site web qui est en fait celui du site artwai.com lui-même. On est sur un site plutôt bien optimisé mais son grand défaut reste le TTFB.
A noter, que les ressources dites statiques sont stockées dans le cache du navigateur et ne sont donc pas rechargées à chaque page. Et si on pouvait faire pareil mais côté serveur…
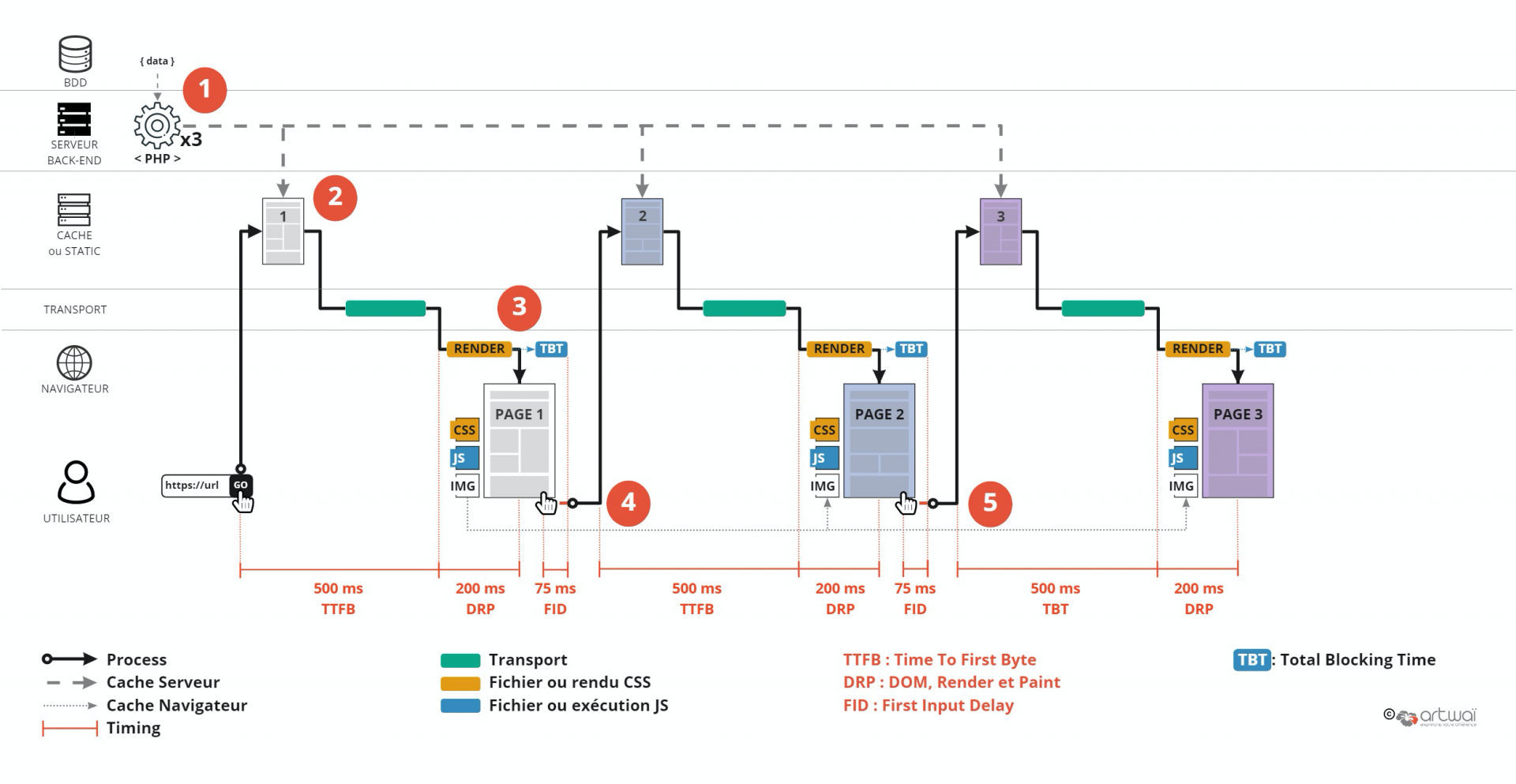
Le reste des étapes 2 à 5 sont similaires au premier schéma.
Cette solution peut être mise en place sur deux niveaux :
Cette solution ne change rien à la conception du code. On garde les mêmes avantages et inconvénients d’un code où les requêtes et le templating peuvent être mélangés.
Le gros inconvénient : les pages sont statiques, elles ne peuvent pas être dynamiques selon le contexte utilisateur. Vous ne pouvez pas gérer un panier de commande par exemple.
Pour faire simple, avec un site bien conçu, dont l’exécution du code côté serveur est bien optimisé, on peut se permettre de faire cohabiter les 2 solutions en excluant les pages qui doivent être dynamiques du processus de mise en cache côté serveur.
Avec cette solution on corrige le principal point faible d’une conception classique, à savoir le TTFB. Par exemple, sur nos schémas, on constate que celui-ci passe de 700 à 500 ms ! Pour info, le site artwai.com repose sur cette solution.
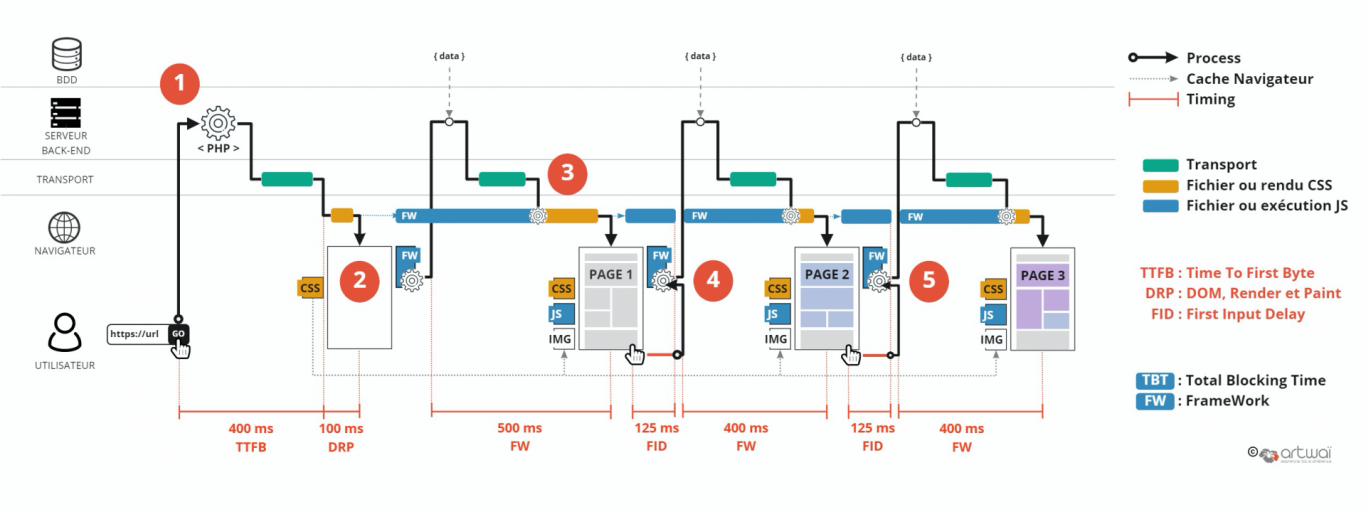
Avec cette conception de site web utilisant Vue.js, React, Angular ou autres, on est entièrement dépendant de l’appareil de l’utilisateur. C’est lui qui manipule le DOM pour modifier l’affichage. Avec l’inconvénient, que si l’appareil dispose de peu de ressources, d’être plus lent que prévu.
A l’inverse, l’avantage est que les requêtes au serveur sont plus courtes car on ne charge que de la donnée. Dès lors, chaque nouvelle page est censée s’afficher plus rapidement que la première. De plus, le code est mieux structuré en séparant les données et le templating, généralement en fonctionnant par composant.
D’un point de vue SEO, cela pose un autre problème. Si l’exécution du JS pour rendre la première page prend plus de 500ms, le moteur de recherche risque de référencer un contenu vide… pas glop !
Alors oui, après le premier chargement, les autres pages sont plus rapides à charger. Mais c’est là que le bas blesse. En effet, c’est présupposer que l’internaute va patiemment attendre ce premier chargement. Car le chargement en 2 étapes est plus long et le FID peut aussi en souffrir, le temps que le JS est bien mis en place toute la page… Sur notre schéma, on perd 400ms de ce point de vue entre le modèle 2 et le modèle 3.
Google l’a bien compris et recommande sérieusement d’améliorer le premier affichage pour conserver votre audience et même votre positionnement.
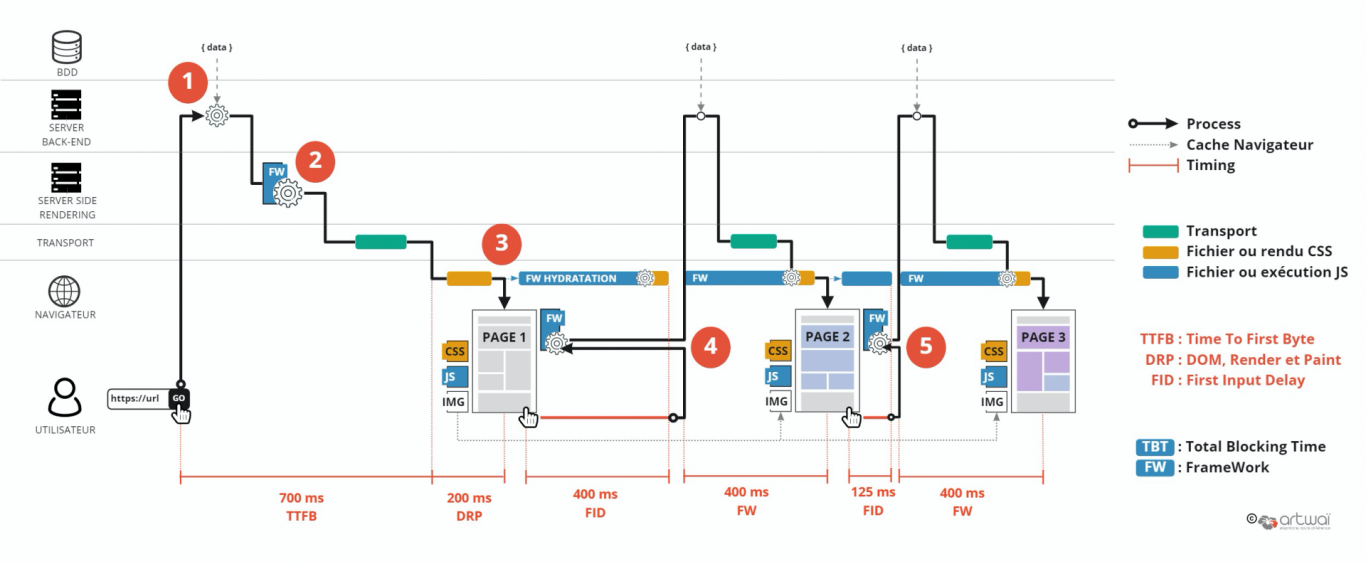
Le server side rendering vient corriger le problème d’un chargement en 2 fois (donc plus lent), et surtout les problèmes de SEO.
Toutefois, côté serveur, nous déportons la création de la page dans le modèle 1, du navigateur vers le serveur. Sorte de retour au source à la conception classique sauf qu’ici le code est le même. Il s’agit du JavaScript. Du coup, le gain en termes de temps de chargement par rapport à une conception classique reste limité.
De plus, l’hydratation ou la réhydratation doit convertir, via JavaScript, une page Web statique en une page Web dynamique, en attachant des gestionnaires d’événements aux éléments HTML. Et cela peut prendre du temps, compliquant par la même le FID, car l’utilisateur ne peut interagir de suite avec la page… Pour éviter cette attente, on voit se multiplier les écrans de chargement ou les skeletons. En le faisant patienter, ils empêchent ainsi l’internaute de cliquer trop tôt.
Ce modèle conserve toutefois l’avantage que les chargements suivants sont censés être plus rapides.
Le premier chargement redevient acceptable avec TTFB plus rapide que précédemment. Le souci vient donc essentiellement de la chaîne JavaScript qui ralentit le FID.
L’une des solutions est d’effectuer une hydratation partielle et/ou progressive pour limiter le TBT.
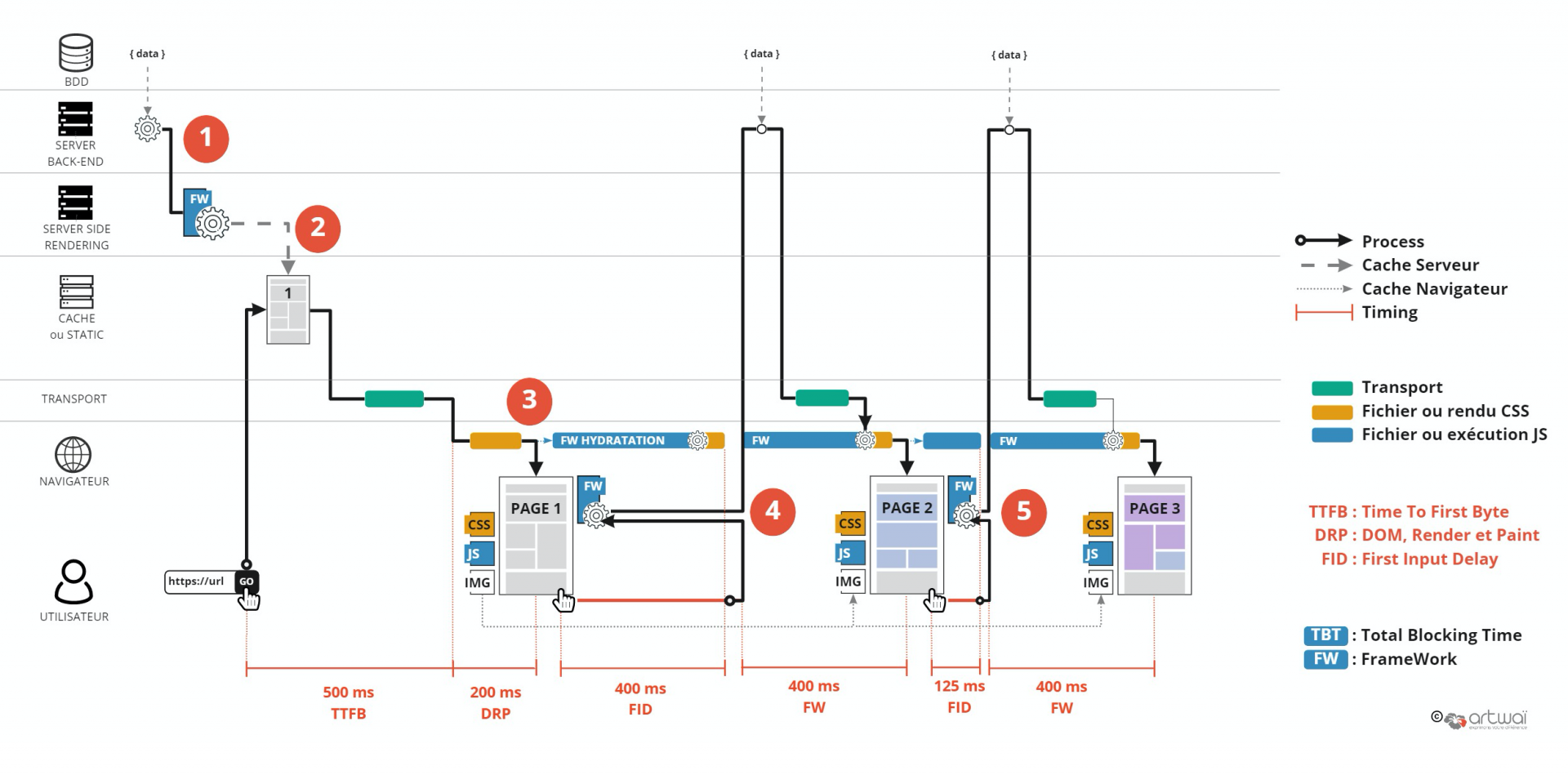
Avec un cache côté serveur, on va encore gagner un peu de temps au premier chargement, de la même manière qu’entre le modèle 1 de conception de site web et le modèle 2.
On pourrait même imaginer mettre en cache toutes les requêtes avec un Varnish par exemple.
Par contre, en terme de complexité nous avons donc plusieurs niveaux de couche à bien configurer pour que tout cela soit bien stable.
Avec le cache, le premier chargement a un TTFB rapide mais le souci reste la réhydratation avec les mêmes solutions citées pour le modèle 4.
À la question « Est-ce qu’il y a un modèle de conception de site web meilleur que les autres ? »,
je répond « Bien sûr que non ça serait trop simple ».
Tout dépend de votre besoin et des interactions attendus des internautes :
Cela peut vous surprendre de la part de quelqu’un qui prône le No Fucking JS Spirit, mais dans l’absolu une technologie n’est pas une mauvaise chose en soit, c’est ce qu’on en fait. Si votre projet repose sur ces 2 critères :
Alors, un framework JS et son infrastructure plus complexe pourra être utile. Tout est une question de curseur. A partir de quand vous basculez d’un modèle à l’autre ? Un site e-commerce avec quelques produits n’a pas forcément besoin d’un framework JS (et nous ne parlons pas de jQuery). A l’inverse si la boutique en ligne repose sur des milliers de références, sur lesquelles il faut pouvoir filtrer, trier, et rechercher ; on peut envisager une conception de site web différente du modèle classique.
Le modèle de conception classique repose sur des langages et des pratiques dont la longévité et la pérennité ne sont plus à mettre en cause. Ce qui n’est pas le cas des framework JS. Angular a eu son heure de gloire, aujourd’hui React semble avoir la meilleure part mais Vue.js n’est pas loin derrière et Svelte semble déjà être son successeur…
Deux pistes de réflexion que j’ai déjà évoquées mais qu’il est bon de répéter.
Enfin, au travers de ces schémas conçus par notre agence web rennaise, vous comprenez rapidement, que la rapidité présupposée supérieure des Framework JS n’est pas si évidente que ça. Et notez que votre site peut être rapide, respecter les seuils des Web Vitals avec une conception classique tout en restant simple à mettre en œuvre.
Image de une par Wojciech Krakowiak via Pixabay

PHP est un langage de programmation côté serveur utilisé pour créer des pages web dynamiques. Il est largement utilisé pour gérer les bases de données, traiter des formulaires, et générer du contenu HTML. Voir la définition complète
MySQL est un système de gestion de bases de données relationnelles open-source, utilisé pour stocker et gérer des données. Il fonctionne avec SQL (Structured Query Language) pour interagir avec les bases de données. Voir la définition complète
Le Server-Side Rendering (SSR) est une technique où le contenu d'une page web est généré sur le serveur, puis envoyé entièrement rendu au navigateur, ce qui améliore les performances et le SEO. Voir la définition complète
Le templating est une technique de développement web permettant de générer dynamiquement des pages HTML en utilisant des modèles préconçus qui sont remplis avec des données lors de l'exécution. Voir la définition complète
Le DOM (Document Object Model) est une représentation en structure d'arbre d'un document HTML ou XML, permettant aux développeurs d'accéder et de manipuler dynamiquement les éléments d'une page web via des langages de programmation comme JavaScript. Voir la définition complète
Le First Input Delay (FID) est une métrique qui mesure le temps écoulé entre la première interaction de l'utilisateur avec une page web (clic, touche) et la réponse du navigateur, reflétant la réactivité du site. Voir la définition complète
Le Total Blocking Time (TBT) est une métrique de performance web qui mesure le temps pendant lequel une page web reste bloquée et ne répond pas aux interactions utilisateur, de l'apparition du premier contenu jusqu'à l'interactivité complète. Voir la définition complète
Le modèle MVC (Modèle-Vue-Contrôleur) est un schéma d'architecture logicielle qui sépare une application en trois composants : le modèle (données), la vue (interface utilisateur) et le contrôleur (logique de traitement), facilitant la maintenance et le dé Voir la définition complète
Le TTFB (Time to First Byte) est une métrique qui mesure le temps écoulé entre l'envoi d'une requête par un navigateur et la réception du premier octet de réponse du serveur, reflétant la réactivité du serveur. Voir la définition complète
Le HTTP (HyperText Transfer Protocol) est un protocole utilisé pour transférer des données sur le web, permettant la communication entre un navigateur et un serveur pour afficher des pages web. Voir la définition complète
Le référencement naturel, ou SEO (Search Engine Optimization), est l'ensemble des techniques visant à améliorer la visibilité d'un site web dans les résultats de recherche des moteurs comme Google, sans utiliser de publicité payante. Voir la définition complète
Le back-end est la partie d'un site web ou d'une application qui fonctionne côté serveur. Il gère la logique, les bases de données, et le traitement des données, invisible pour l'utilisateur final. Voir la définition complète
Une URL (Uniform Resource Locator) est l'adresse unique d'une ressource sur Internet, comme une page web, une image ou un fichier, permettant de la localiser et d'y accéder via un navigateur. Voir la définition complète
L'hydratation, en développement web, est le processus par lequel un site généré côté serveur devient interactif côté client en liant les éléments HTML statiques à du JavaScript pour activer des fonctionnalités dynamiques. Voir la définition complète
Le cache est un espace de stockage temporaire qui conserve des données fréquemment utilisées pour accélérer leur accès ultérieur, réduisant ainsi les temps de chargement et la consommation de ressources. Voir la définition complète
Un framework est un ensemble d'outils et de bibliothèques qui fournit une structure et des fonctionnalités préétablies pour développer des applications, simplifiant ainsi le travail des développeurs en offrant des solutions prêtes à l'emploi. Voir la définition complète
JavaScript est un langage de programmation dynamique principalement utilisé pour ajouter des fonctionnalités interactives aux pages web. Il permet de manipuler le DOM, de gérer des événements, et d'effectuer des requêtes asynchrones. Voir la définition complète
Une Single Page Application (SPA) est une application web qui charge une seule page HTML et met à jour dynamiquement son contenu en réponse aux interactions utilisateur, sans recharger entièrement la page. Voir la définition complète
Vanilla JS fait référence à l'utilisation de JavaScript pur, sans frameworks ou bibliothèques supplémentaires, pour développer des applications ou des fonctionnalités web. Voir la définition complète
Le HTML (HyperText Markup Language) est le langage standard utilisé pour structurer et afficher le contenu sur le web. Il définit des éléments comme les titres, paragraphes, liens, images, et autres composants d'une page web. Voir la définition complète
Le CSS (Cascading Style Sheets) est un langage utilisé pour décrire l'apparence et la mise en page des documents HTML, en définissant des styles comme les couleurs, polices, marges, et positionnements des éléments sur une page web. Voir la définition complète
Opquast est un ensemble de bonnes pratiques et de certifications pour améliorer la qualité et l'accessibilité des sites web, couvrant des aspects comme l'ergonomie, la performance, la sécurité et le référencement. Voir la définition complète
L'intégration consiste à assembler des éléments visuels (HTML, CSS, JavaScript) pour transformer des maquettes graphiques en pages web fonctionnelles et interactives, tout en respectant les standards du web. Voir la définition complète
WordPress est un système de gestion de contenu (CMS) open-source qui permet de créer et gérer facilement des sites web, des blogs et des boutiques en ligne sans compétences en programmation. Voir la définition complète